Prometheus 理论与实践
Prometheus 理论与实践
Prometheus
监控设计
监控分类
业务监控- 包含 用户访问QPS、DAU日活、访问状态、业务接口、产品转化率、业务异常数据等.系统监控- 包含 系统相关的 CPU、内存、磁盘容量、磁盘IO、TCP连接、网络接口流量、连接数等.网络监控- 包含 网络状态的一些监控 丢包率、延迟、连通率等.日志监控- 包含 日志相关的 Error 级别日志、异常的访问记录、自定义日志级别 等.程序监控- 包含 程序相关的 程序接口、程序中链路的状态等.
Prometheus 简介
Prometheus 是一个开源系统监控和报警的工具集合. 由 SoundCloud 公司于2012年开发. 2016年 加入 CNCF 组织. 是继 kubernetes 后 第二个加入 CNCF 组织的成员
Prometheus 特性
基于
time-series时间序列模型.- 时间序列 - 是一些列有序的数据, 通常是相同时间间隔采集的数据.
- 基于
Key/Value的数据模型.
基于 Block (块) 存储.
time-series数据, 每2小时会打包成一个 Block (块).每一个
Block- 分为多个chunk文件.chunk是存储的基本单位,index和metadata是作为子集.chunk文件 - 是用于存放采集的metadata数据文件 和index索引文件.index文件 - 是对metrics和labels进行索引后存储chunk文件中.
数据采集会先存储于内存中从而加快搜索和访问.
- 当出现错误或者宕机时,
Prometheus有一种保护机制叫WAL- 会将数据定期写入磁盘中, 以chunk表示, 系统恢复时会将丢失的数据恢复到内存中.
- 当出现错误或者宕机时,
数据查询 根据 数据运算( + - * / ) 的表达式进行查询. 并且提供了专有的查询
console.- 数据运算表达式:
( 数据A + 数据B ) / 总数据C > 固定百分比
- 数据运算表达式:
基于 HTTP
pull / push两种数据采集传输方式.- 所有数据采集都基于HTTP.
- 精细的数据采集 - Prometheus 的采集间隔基本都是 秒级 的采集.
- 开源、成品的插件多.
Prometheus 概念理论
Prometheus metrics
Prometheus 对于采集的数据统称为
metrics数据.metrics是一种对采集数据的总称, 它不代表某一种具体的数据格式, 是一种对于度量计算单位的抽象.
Gauges
Gauges 最简单的度量指标, 只有一个最简单的返回值, 或者瞬时状态.
- 比如: 磁盘的容量、内存的使用量, 就使用 Gauges 的 metrics 格式来度量. 因为 磁盘容量、内存使用量 都是随时会发生变化, 而且这种变化是无规律的变化. 这种类型的数据就是Gauges类型的代表.
Counters
Counter 就是计数器, 从数据 0 开始累加计算, 正常状况下永远是累加或者不变 不会减少.
- 比如: 用户访问量, 就是一直不断的累加.
Histograms
Histogram 统计数据的分布情况. 最大值、最小值、平均值、中位数、的百分比数值 .
- 比如: 用户响应时间, 每个用户到达服务端的网络请求时间都有差异. 这个时候就可以使用 Histogram 类型分别统计出 影响时间中 快慢的占比. 如 小于 0.5s 占 80% , 大于 1s 占 10% 大于 5s 占 7% 大于10s 的占 3%.
Prometheus K/V 数据形式
Prometheus 中采集的 metrics 数据都是以 key/value 格式形式存储的.
比如: 使用 curl http://localhost:9100/metrics 可以查看到数据采集都是 key/value 格式.
process_max_fds 65535前面是 key 空格后是 value .
Prometheus exporter
为 Prometheus 提供监控数据源的应用都被统称为 exporter. 如:
blackbox_exporter– 黑盒数据采集插件, 采集一些最基本的数据, 如: 机器连通性、服务是否running、端口是否打开 等.node_exporter– Linux 系统相关的数据采集插件.
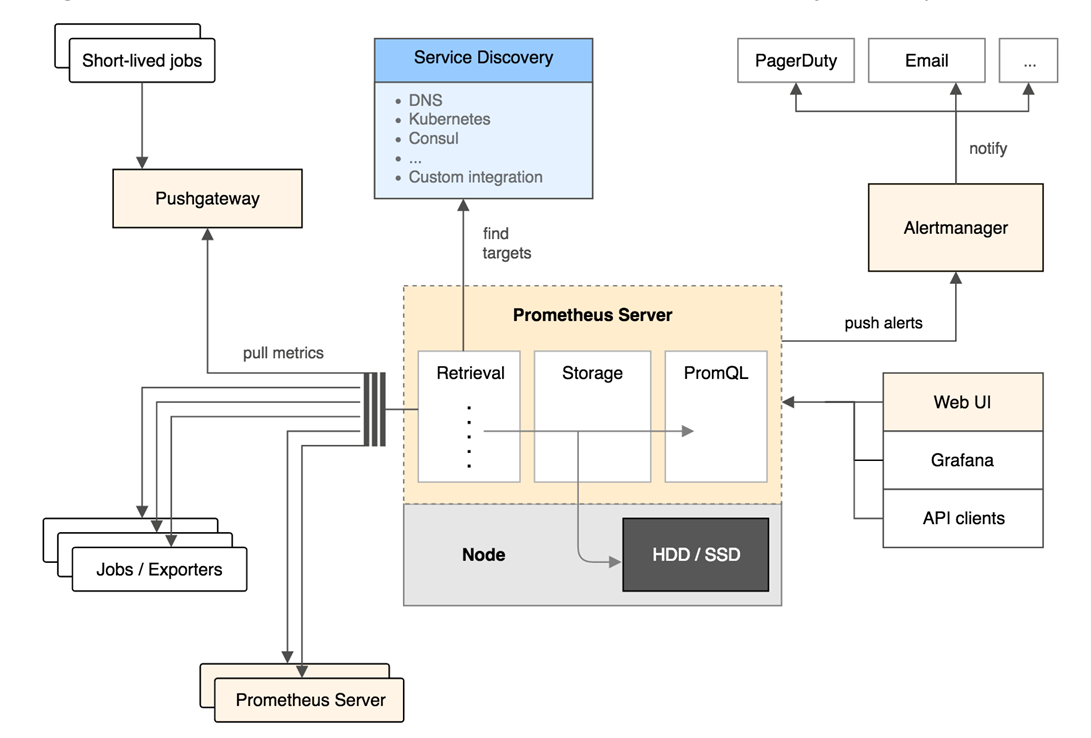
Prometheus Server 提供PromQL查询语言能力、负责数据的采集和存储等主要功能.
数据的采集主要通过周期性的从 exporter 所暴露出来的HTTP服务地址 ( /metrics ) 来获取监控数据。
exporter 在实际运行的时候根据其支持的方式也会分为:
独立运行的 exporter 应用, 通过HTTP服务地址提供相应的监控数据. 如:
node_exporter内置在监控目标中, 通过HTTP服务地址提供相应的监控数据. 如:
kubernetes
Prometheus pushgateway
- pushgateway 本身是一个 HTTP 服务器. 用户通过将采集的数据推送到 pushgateway 中, 然后再由 Prometheus Pull 下来.
PrometheusRules 告警规则
Prometheus Operator模式中,告警规则(Rules) 是一个通过 Kubernetes API 声明式创建的一个资源清单
PrometheusRules支持 两种 类型的规则记录规则
record- 记录规则主要是为了简写报警规则和提高规则复用以及提高性能. 记录规则是顺序执行, 后面的规则可以引用前面定义好的规则.- 记录规则
record- 允许您预计算经常需要或计算开销大的表达式,并将其结果保存为一组新的时间序列。查询预计算的结果通常比每次需要时执行原始表达式快得多。这对于仪表板grafana特别有用,因为仪表板每次刷新时都需要重复查询同一表达式。
- 记录规则
报警规则
alert- 报警规则是真正去判定是否需要报警的规则, 报警规则中可以使用记录规则.
PrometheusRules 资源清单
Prometheus-Record:
| |
Prometheus-Alert
| |
groups- 告警规则的组, 每个资源清单都包含一个groups一个rules以及 多个alertorrecord规则.name- 告警规则的名称.rules- 具体的告警规则.expr- 待评估项PromQL表达式, 每个评估周期都会在当前时间进行评估,并将结果记录为一组新的时间序列,其中度量标准名称由 记录 给出。alert- 告警规则的名称record- 记录规则中使用, 要输出的时间序列的名称. 必须是有效的度量标准名称.for- 使 Prometheus 在第一次遇到新的表达式输出向量元素和将此警告作为此元素的触发计数之间等待一段时间.labels- 指定要附加到警报的一组附加标签. 任何现有的冲突标签都将被覆盖. 支持模板语法.annotations- 额外的 注释/信息 标签,可用于存储更长的附加信息,例如警报描述或链接. 支持模板语法.
FAQ -
PrometheusRules资源清单中的变量PrometheusRules资源清单中的变量与Helm中的变量都使用 temlpate 模板中的定义方式{{ }}Helm 使用时会出现 变量未定义的情况.- 解决方式: 将 {{ }} 定义为 {{
{{}} $value {{}}}}
- 解决方式: 将 {{ }} 定义为 {{
PromQL 语法
Prometheus 提供一个函数式的表达式语言 PromQL (Prometheus Query Language), 可以使用户实时地查找和聚合时间序列数据. 表达式计算结果可以在图表中展示,也可以在 Prometheus 表达式浏览器中以表格形式展示, 或者作为数据源, 以HTTP API的方式提供给外部系统使用.
Prometheus 的 PromQL (表达式语言) 中, 任何表达式或者子表达式都可以归为四种类型:
string(字符串) — 一个当前没有被使用的简单字符串.scalar(标量) — 一个简单的浮点值.instant vector(瞬时向量) — 它是指在同一时刻, 抓取的所有度量指标数据. 这些度量指标数据的key都是相同的, 也即相同的时间戳.range vector(范围向量) — 它是指在任何一个时间范围内, 抓取的所有度量指标数据.
PromQL字面量
字符串
字符串可以用单引号,双引号或反引号指定为文字.
PromQL 遵循与Go相同的转义规则. 在单引号,双引号中,反斜杠成为了转义字符. 但是反引号 内不处理转义字符. PromQL 不会丢弃反引号中的换行符.
浮点数标量
- 标量浮点值可以直接写成形式
[-](digits)[.(digits)]既-2.43.
瞬时向量
瞬时向量选择器允许在给定时间戳(即时)为每个选择一组时间序列和单个样本值:在最简单的形式中,仅指定度量名称. 这会生成包含具有此度量标准名称的所有时间序列的元素的即时向量
通过在度量指标后面增加{}一组标签可以进一步地过滤这些时间序列数据.
采用不匹配的标签值也是可以的,或者用正则表达式不匹配标签. 标签匹配如下:
=- 精确地匹配标签给定的值!=- 不等于给定的标签值=~- 正则表达匹配给定的标签值!~- 给定的标签值不符合正则表达式正则表达式使用 RE2 语法:
https://github.com/google/re2/wiki/Syntax
例:
| |
| |
| |
范围向量
范围向量文字像即时向量文字一样工作,除了它们从当前时刻选择一系列样本. 在语法上,范围持续时间附加在向量选择器末尾的方括号([])中,以指定应为每个结果范围向量元素提取多长时间值。
持续时间指定为数字, 后面是以下单位之一
s- secondsm- minutesh- hoursd- daysw- weeksy- years
例:
| |
偏移修饰符 offset
这个
offset偏移修饰符允许在查询中改变单个瞬时向量和范围向量中的时间偏移. 简单来说就是 - 假设当前时间为10:00:00使用偏移修饰符 offset 1w , 既查询 1个周前10:00:00的时间序列记录.offset必须直接包含在选择器后面.
例:
| |
| |
聚合操作符
聚合操作符 用于聚合单个即时向量的元素,从而生成具有聚合值的较少元素的新向量.
sum- 在维度上求和max- 在维度上求最大值min- 在维度上求最小值avg- 在维度上求平均值stddev- 求标准差stdvar- 求方差count- 统计向量元素的个数count_values- 统计相同数据值的元素数量bottomk- 样本值第k个最小值topk- 样本值第k个最大值quantile- 统计分位数
sum
sum在维度上求和by的含义表示将结果根据 instance 来进行区分. 跟 mysql 语句中 group by 差不多.
例:
| |
Prometheus 告警
告警能力在
Prometheus的架构中被划分成两个独立的部分 ( PrometheusRules 和 Alertmanager )。- 通过在
Prometheus中定义AlertRule(告警规则), Prometheus 会周期性的对告警规则进行计算, 如果满足告警触发条件就会向Alertmanager发送告警信息。
- 通过在
在
Prometheus中一条告警规则主要由以下部分组成告警名称: - 用户需要为告警规则命名, 当然对于命名而言, 需要能够直接表达出该告警的主要内容。
告警规则: - 告警规则实际上主要由
PromQL进行定义, 其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警。
在
Prometheus中还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。Alertmanager- 作为一个独立的组件, 负责接收并处理来自Prometheus的告警信息。Alertmanager- 可以对这些告警信息进行进一步的处理, 比如当接收到大量重复告警时能够消除重复的告警信息, 同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件,Slack等多种通知方式的支持, 同时还支持与Webhook的集成, 以支持更多定制化的场景。目前Alertmanager还不支持钉钉, 那用户完全可以通过Webhook与钉钉机器人进行集成, 从而通过钉钉接收告警信息。同时AlertManager还提供了 静默 和 告警抑制机制 来对告警通知行为进行优化。
Alertmanager 特性
Go Template渲染警报内容, 使用{{ }}定义模板, 让报警内容更直观, 好看。根据标签定义警报路由, 实现警报的优先级、接收人划分, 并针对不同的优先级和接收人定制不同的发送策略。
AlertManager 告警分组
告警分组机制 - 可以将详细的告警信息合并成一个通知。在某些情况下, 比如由于系统宕机导致大量的告警被同时触发, 在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知, 避免一次性接受大量的告警通知, 而无法对问题进行快速定位。
当集群中有数百个正在运行的服务实例, 并且为每一个实例设置了告警规则。假如此时发生了网络故障, 可能导致大量的服务实例无法连接到数据库, 结果就会有数百个告警被发送到
Alertmanager。而作为用户, 可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组, 而将这些告警内聚在一起成为一个通知。告警分组, 告警时间, 以及告警的接受方式可以通过
Alertmanager的配置文件进行配置。
AlertManager 抑制
抑制 - 是指当某一告警发出后, 可以停止重复发送由此告警引发的其它告警的机制。
当集群不可访问时触发了一次告警, 通过配置
Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。抑制 通过
Alertmanager的配置文件进行设置。
AlertManager 静默
静默 - AlertManager 提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,
Alertmanager则不会发送告警通知。静默 设置需要在
Alertmanager的Web页面上进行设置。
Alertmanager 内部架构图

架构图流程解析
从左上开始, Prometheus 发送的警报到 Alertmanager;
警报会被存储到
AlertProvider中, Alertmanager 的内置实现就是包了一个map, 也就是存放在本机内存中, 这里可以很容易地扩展其它Provider;Dispatcher是一个单独的goroutine, 它会不断到AlertProvider拉新的警报, 并且根据 YAML 配置的Routing Tree将警报路由到一个分组中;分组会定时进行
flush(间隔为配置参数中的 group_interval),flush后这组警报会走一个Notification Pipeline链式处理;Notification Pipeline为这组警报确定发送目标, 并执行 抑制逻辑, 静默逻辑, 去重逻辑, 发送与重试逻辑, 实现警报的最终投递;
Routing Tree
Routing Tree的是一颗多叉树, 节点的数据结构定义如下具体的处理代码很简单,深度优先搜索:
- 警报从 root 开始匹配(root 默认匹配所有警报).
- 然后根据节点中定义的
Matchers检测警报与节点是否匹配, 匹配则继续往下搜索, 默认情况下第一个 深度的Match(也就是 DFS 回溯之前的最后一个节点)会被返回。
- 然后根据节点中定义的
- 特殊情况就是节点配置了
Continue=true, 这时假如这个节点匹配上了, 那不会立即返回, 而是继续搜索, 用于支持警报发送给多方这种场景(比如 “抄送”, 多告警媒介的发送)
- 特殊情况就是节点配置了
| |
| |
Routing Tree的设计意图是让用户能够非常自由地给警报归类, 然后根据归类后的类别来配置要发送给谁以及怎么发送.发送给谁– 按照定义的匹配规则, 定义好特定的接收组, 都没有匹配上那么就是 默认警报, 发送给默认接收组.如何发送group_by– 决定了警报怎么分组, 每个group只会定时产生一次通知, 这就达到了降噪的效果, 而不同的警报类别分组方式显然是不一样的.group_interval和group_wait– 控制分组的细节, 其中group_interval控制了这个分组最快多久执行一次Notification Pipeline.repeat_interval– 假如一个相同的警报一直FIRING,Alertmanager并不会一直发送警报, 而会等待一段时间, 这个等待时间就是repeat_interval, 显然,不同类型警报的发送频率也是不一样的.
Notification Pipeline
由
Routing Tree分组后的警报会触发Notification Pipeline当一个
AlertGroup新建后, 它会等待一段时间(group_wait 参数), 再触发第一次Notification Pipeline.假如这个
AlertGroup持续存在, 那么之后每隔一段时间(group_interval 参数), 都会触发一次Notification Pipeline.每次触发
Notification Pipeline,AlertGroup都会将组内所有的Alert作为一个列表传进Pipeline,Notification Pipeline本身是一个按照责任链模式设计的接口,MultiStage这个实现会链式执行所有的Stage.MultiStage里就是架构图里画的InhibitStage、SilenceStage… 这么一条链式处理的流程. 这里重点要说的是DedupStage和NotifySetStage它俩协同负责去重工作.NotifySetStage会为发送成功的警报记录一条发送通知,key是 ‘接收组名字’ + ‘GroupKey’ 的 key 值,value是当前 Stage 收到的 []Alert (这个列表和最开始进入Notification Pipeline的警报列表有可能是不同的, 因为其中有些 Alert 可能在前置 Stage 中已经被过滤掉了)DedupStage中会以 ‘接收组名字’ + ‘GroupKey’ 的 key 值 为 key 查询通知记录, 假如查询无结果, 那么这条通知没发过, 为这组警报发送一条通知;
查询有结果, 那么查询得到已经发送过的一组警报
S, 判断当前的这组警报A是否为S的子集.假如
A是S的子集, 那么表明A和S重复, 这时候要根据repeat_interval来决定是否再次发送;距离
S的发送时间已经过去了足够久repeat_interval, 那么我们要再发送一遍;距离
S的发送时间还没有达到repeat_interval, 那么为了降低警报频率, 触发去重逻辑, 这次我们就不发了;
假如 A 不是 S 的子集,那么 A 和 S 不重复,需要再发送一次;
假如一个
AlertGroup里的警报一直发生变化, 那么虽然每次都是新警报, 不会被去重, 但是由于group_interval(假设是5分钟)存在, 这个AlertGroup最多 5 分钟触发一次Notification Pipeline, 因此最多也只会 5 分钟发送一条通知;假如一个
AlertGroup里的警报一直不变化, 就是那么几条一直 FIRING 着, 那么虽然每个group_interval都会触发Notification Pipeline, 但是由于repeate_interval(假设是1小时)存在, 因此最多也只会每 1 小时为这个重复的警报发送一条通知;Silence和Inhibit, 两者都是基于用户主动定义的规则的.Silence Rule– 静默规则用来关闭掉部分警报的通知, 比如某个性能问题已经修复了, 但需要排期上线, 那么在上线前就可以把对应的警报静默掉来减少噪音;Inhibit Rule– 抑制规则用于在某类警报发生时, 抑制掉另一类警报, 比如某个机房宕机了, 那么会影响所有上层服务, 产生级联的警报洪流, 反而会掩盖掉根本原因, 这时候抑制规则就有用了;
- 综上所述
Notification Pipeline的设计意图就很明确了 — 通过一系列逻辑(如抑制、静默、去重)来获得更高的警报质量, 由于警报质量的维度很多(剔除重复、类似的警报, 静默暂时无用的警报, 抑制级联警报), 因此Notification Pipeline设计成了责任链模式, 以便于随时添加新的环节来优化警报质量。
AlertManager 配置文件
AlertManagerRoute 路由配置 –AlertManager配置文件中比较重要的点是Route的配置, 可以使我们的告警根据不同的标签告警到不同的渠道。Alertmanager的设计是根节点的所有参数都会被子节点继承(除非子节点重写了这个参数)。
| |
- 例子:
| |
AlertManager主要处理流程接收到
Alert,根据 labels 判断属于哪些 Route(可存在多个Route,一个Route有多个Group,一个Group有多个Alert)。将
Alert分配到 Group中, 没有则新建 Group 。新的 Group 等待
group_wait指定的时间(等待时可能收到同一Group的 Alert), 根据resolve_timeout判断Alert是否解决, 然后发送通知。已有的 Group 等待
group_interval指定的时间, 判断Alert是否解决, 当上次发送通知到现在的间隔大于repeat_interval或者 Group 有更新时会发送通知。